We all play club pairs type games and we always see daft 3NT contracts on the traveller when we play in 4/
(just because we have an 8 or 9 card fit). Maybe some simulations on the matchpoint benefits/ lack thereof of random 3NT punts would be good. Or just some definitive answer as to how much the computer says they should be losing by...
It's a bit hard to define what a "random 3NT punt" is, so I'm going to reword the question like this:
Partner opens 1NT and we have any balanced hand worth 3NT, regardless of major length. Of the hands where we have an 8-card major fit, how much better is it to play there than to play in 3NT?
In fact, I'm just going to restrict it to hands where we have a heart fit as it makes no difference. The criteria are as follows:
- Partner is 12-14 balanced
- RHO has 0-14 points and 7 losers or worse
- We have 12-18 balanced
- We have 8+ hearts between us
Over 25,000 tests, we see the following:
Tricks 3NT 4
0 0 0
1 0 0
2 1 0
3 4 0
4 12 0
5 94 1
6 490 20
7 1893 160
8 4785 1129
9 6660 4898
10 5555 9249
11 3780 7075
12 1528 2195
13 198 273
So, on that evidence, it seems that just punting 3NT has a lot going for it. It's a loser, but not by very much so if you fancy a swing then it might be worth a shot. Incidentally, at IMPs scoring you lose 1.02 IMPs/board by bidding 3NT, so it's really not a good idea.
NT is best: 10280
Hearts is best: 12619
Both the same: 2101
Some experienced players will be shifting around in their seats now, crying that this is rubbish analysis. Yep, it is. The criteria are too general. We know from playing lots of bridge that if you have thin game values, you'd rather be in the major but if you have plenty of extras then the need to ruff losers isn't so great and 3NT will often make the same number of tricks. Also, we know that with a 4333 hand we will usually just bid 3NT over 1NT regardless of whether we have a major or not as it's likely to play the same. So let's break it down.
Using test runs of 1000:
Your point count
12-13 14-15 16-18
NT is best: 345 454 623
Hearts is best: 522 500 371
Both the same: 133 46 6
NT IMPs: -1.23 -0.96 -0.66
Combined Hearts
8 9 10
NT is best: 421 354 236
Hearts is best: 483 591 689
Both the same: 96 55 75
NT IMPs: -0.81* -2.16 -2.76
Your hand shape
3433 2533 4432
NT is best: 467 458 324
Hearts is best: 393 473 561
Both the same: 140 69 115
NT IMPs: +0.59 -1.07 -1.64
Now, I should probably break it down even further and find out what point ranges are best for 3NT in a 5-3 fit etc. etc. but that's going a bit over the top, I think. Generally speaking: 4333 shapes indicate 3NT; stronger point counts indicate 3NT; 5-3 fits indicate 3NT. Combining these factors will just do what you expect it to do.
Type of fit
4-4 5-3
NT is best: 339 516
Hearts is best: 549 401
Both the same: 112 83
NT IMPs: -0.75* -0.23*
Note that punting 3NT is never a really stupid thing to do at pairs. Even if you have a 5-5 heart fit that you're missing, you'll still get a good result about a quarter of the time! Note also that playing in 3NT is almost always a substantial loser at IMPs, the only exception being when you're 4333. So punting 3NT and eschewing your major is purely a pairs manoeuvre.
This is just a brief skimming of this area as the subject of 3NT simulations seems to have been done to death on rec.games.bridge. Try this thread for starters.
So to answer Phil's question, those bastards who punt 3NT and get a good result against you are indeed being lucky, but not as lucky as you might have first thought.
* Edit: see comments for slightly more accurate results.
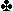 opening showed either 10 points or 30. You want to run a simulation based upon this opening and so you need to deal out a bunch of hands which fit. So you tell the computer to give you some hands with 10 points and some hands with 30 points and go on your merry way.
opening showed either 10 points or 30. You want to run a simulation based upon this opening and so you need to deal out a bunch of hands which fit. So you tell the computer to give you some hands with 10 points and some hands with 30 points and go on your merry way. A J 7 6 2
A J 7 6 2